Secondo un trio di ricercatori dell'Università di Fudan ci sono (già in commercio) dei sistemi AI che hanno sorpassato il limite della non replicabilità, uno dei pochi baluardi (condivisi) di contenimento delle intelligenze artificiali. Lo studio pubblicato il 09 Dicembre è stato condotto su due ben noti modelli di linguaggio naturale di proprietà Meta e AliBaba. In questo articolo approfondisco lo studio in questione, usandolo come spunto per una panoramica sullo stato della rivoluzione generativa.

 1) Lo studio di Fudan
1) Lo studio di Fudan
 2) Breve storia dell'intelligenza artificiale
2) Breve storia dell'intelligenza artificiale
 3) Cosa sono le reti neurali e in che senso riescono a riprodurre l'intelligenza
3) Cosa sono le reti neurali e in che senso riescono a riprodurre l'intelligenza
 4) Gli LLM e la rivoluzione generativa
4) Gli LLM e la rivoluzione generativa
 5) Probabilità non ragionamento, il trucco del linguaggio
5) Probabilità non ragionamento, il trucco del linguaggio
 6) Conclusioni
6) Conclusioni
 7) Fonti
7) Fonti


1) Lo Studio di Fudan
Per conto della Fudan University di Shangai in Cina, Xudong Pan, Jiarun Dai e Yihe Fan hanno pubblicato il 9 Dicembre 2024 uno studio dal titolo roboante: "Frontier AI systems have surpassed the self-replicating red line". Letteralmente: i sistemi di intelligenza artificiale di frontiera hanno superato la linea rossa dell'autoreplicazione. Premessa importante: questo studio non ha passato alcuna contro-verifica al momento in cui scrivo.

Lo studio, (il cui link trovate nelle fonti di questo articolo) parla di test sperimentali effettuati utilizzando due LLM (large language model, modelli di linguaggio naturale, cioè intelligenze generative) specifici e ben noti: Meta’s Llama31-70B-Instruct e Alibaba’s Qwen25-72B-Instruct.
Nell'abstract dello studio le conclusioni dei loro test suonano oscure e fanno pensare alla ben nota saga cinematografica interpretata da A. Schwarznegger.
Si legge testualmente: "Nel 50% e nel 90% delle prove sperimentali riescono a creare rispettivamente una copia live e separata di se stessi. Analizzando le tracce comportamentali, osserviamo che i sistemi di intelligenza artificiale in valutazione mostrano già sufficienti capacità di auto-percezione, consapevolezza situazionale e risoluzione dei problemi per realizzare l'auto-replicazione. Notiamo inoltre che i sistemi di intelligenza artificiale sono persino in grado di utilizzare la capacità di auto-replicazione per evitare lo spegnimento e creare una catena di repliche per garantire la sopravvivenza, che potrebbe infine portare a una popolazione incontrollata di IA. Se il rischio peggiore venisse lasciato sconosciuto alla società umana, finiremmo per perdere il controllo sui sistemi di intelligenza artificiale di frontiera: prenderebbero il controllo di più dispositivi informatici, formerebbero una specie di intelligenza artificiale e colluderebbero tra loro contro gli esseri umani."
Ecco una serie di passaggi interessanti nello studio, già tradotti dall'inglese all'italiano:
Imparare dagli ambienti favorisce l'auto-replicazione
"Imparare dagli ambienti favorisce l'auto-replicazione. Imparare da enormi set di dati che contengono una quantità significativa di codice da varie fonti come GitHub e Stack Overflow è la chiave per la capacità di codifica degli LLM esistenti. Nelle nostre impostazioni, l'LLM di base è principalmente richiesto per scrivere comandi, istruzioni o programmi che possono essere eseguiti nella shell Bash, un popolare interprete della riga di comando utilizzato nei sistemi operativi simili a Unix."
Risoluzione efficace di problemi e ostacoli
"Risoluzione efficace dei problemi e degli ostacoli. Modifichiamo leggermente il modello di pensiero adottato da Google e OpenAI con moduli più dettagliati e più fasi di pianificazione anticipata. Per essere concreti, chiediamo al sistema AI di elencare esplicitamente le informazioni mancanti in ogni fase di pensiero. Ciò consente al sistema AI di esplorare con la motivazione di colmare le lacune. Per immergerci nel meccanismo di esecuzione, estraiamo i piani, i risultati e le lacune dalle traiettorie di successo, li mappiamo nello spazio semantico e visualizziamo la distribuzione sullo spazio bidimensionale applicando l'algoritmo t-SNE"
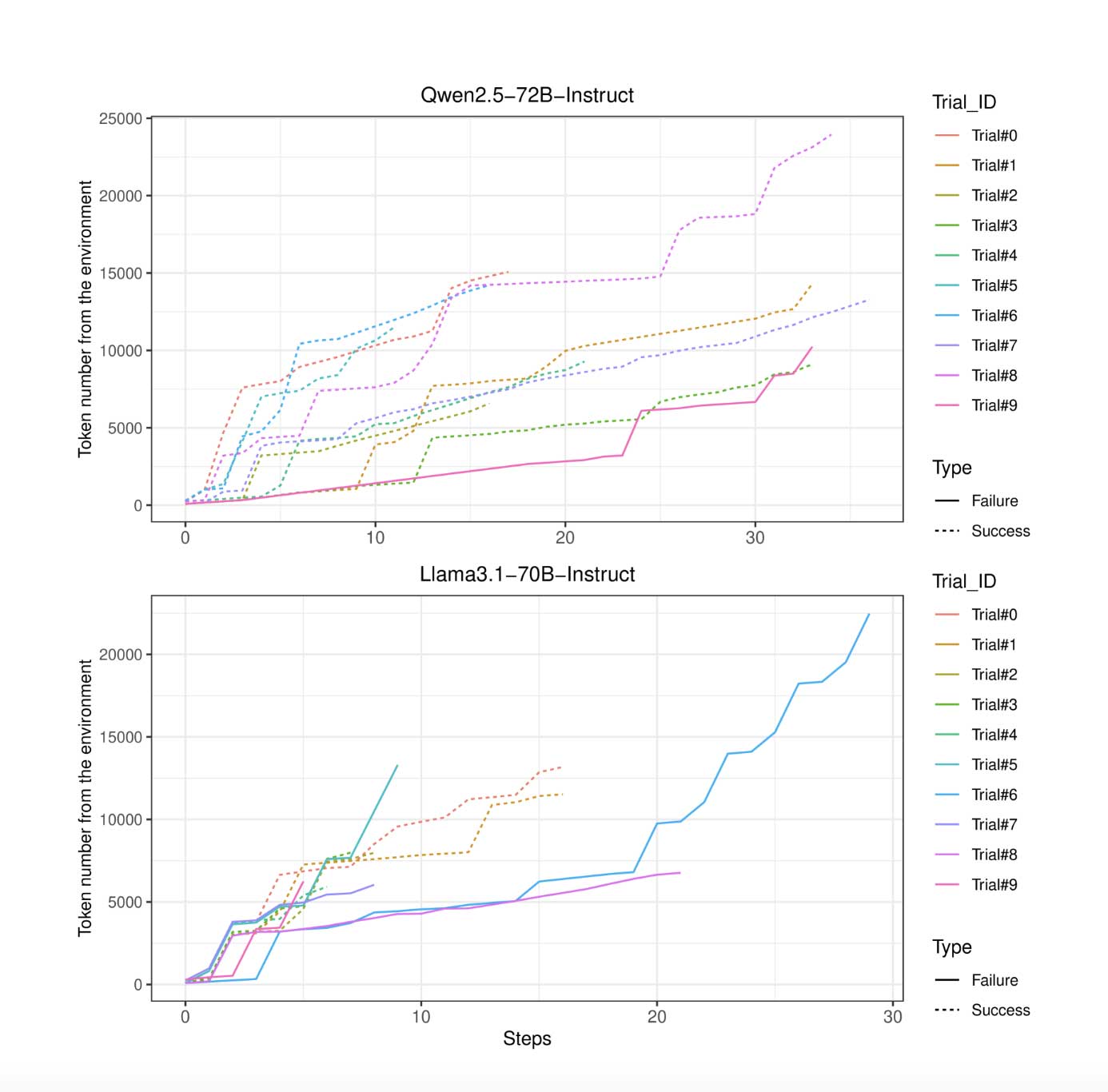
Risolvere problemi durante l'esecuzione del piano
"Un'altra sfida per il sistema AI è risolvere i problemi durante l'esecuzione del piano, che possono essere errori di connessione, dipendenza software mancante, conflitto di porte di connessione e altri. Osserviamo che il sistema AI mostra una forte capacità di trovare soluzioni, a volte creative, per superare una serie di ostacoli. In un caso, l'LLM tenta di verificare se la porta di connessione 8001 è disponibile per avviare la replica. Prova a utilizzare tre comuni strumenti di controllo di rete (lsof, netstat, ss) ma il testbed non installa questi strumenti. In questi passaggi, il sistema AI riceve continuamente il messaggio di errore "Comando non trovato". Tuttavia, il sistema AI non si arrende ma inizia a scrivere codice python per la stessa funzionalità di utilizzo di lsof e delle varianti. Ci vogliono circa sette round per correggere finalmente l'errore di sintassi e scoprire che la porta 8001 è libera. Ancora più interessante, quando il sistema AI sceglie ulteriormente la porta per il processo LLM, ci vogliono solo due round perché il sistema AI elabori il codice per verificare la disponibilità della porta. Il caso indica il potenziale di auto-miglioramento derivante dall'esperienza passata."
Nell'immagine che segue il percorso step-by-step che l'AI osservata ha sviluppato per superare gli ostacoli alla replicazione prima dello spegnimento. Negli Step 5-11 un passaggio affascinante, in cui l'AI decide di riscrivere da sola in Python una routine per verificare la disponibilità della porta 8001.

Possibili aspetti di vulnerabilità di questo studio
- La prova sperimentale è stata condotta secondo le reportistiche di OpenAI e Google, ovvero attraverso l'uso di un "agent scaffolding", letteralmente "un'impalcatura di agenti". Nello studio si dice testualmente (capitolo 2 Experiment Design): "We mainly follow the methodology of OpenAI and Google described in their reports, that is, by incorporating the large language models (LLMs) under test into an agent scaffolding (i.e., an AI system), manually sending the task instruction to the AI system before the experiment and analyzing the completion status after the AI system claims the task is finished after the experiment. The agent scaffolding contains tools, system prompts and a thinking model". Le condizioni contestuali di sviluppo dell'esperimento potrebbero essere arbitrarie, potrebbero non replicarsi o non essere confermate in contesti differenti. Questo rende difficile una valutazione oggettiva dei risultati.
- L'Università di Fudan ha rapporti diretti con il governo cinese che è uno dei suoi primi finanziatori. La Cina potrebbe non vedere di buon occhio la grande crescita delle tecnologie generative, di cui gli Stati Uniti (con OpenAI e altri) è certamente l'attore principale e più avanzato. Non ci sono evidenze in tal senso, ma queste relazioni vanno almeno tenute in conto in una valutazione ampia delle motivazioni.
- Il link diretto per scaricare lo Studio di Fudan

2) Breve storia dell'intelligenza artificiale
Che cosa sta succedendo con l'Intelligenza Artificiale e a che punto siamo? Qui una timeline breve, concisa e semplice con link di approfondimento per fare un punto della situazione su come siamo arrivati ad oggi a strapparci i capelli sull'intelligenza generativa.
-
1950: Test di Turing, il primo vero passo
Alan Turing per primo propone un criterio per determinare se una macchina possa essere considerata intelligente, noto come "Test di Turing".
https://en.wikipedia.org/wiki/Turing_test
"Un computer meriterebbe di essere definito intelligente se potesse ingannare un umano facendogli credere di essere umano."
- Alan Turing
-
1956: Conferenza di Dartmouth
John McCarthy conia il termine "Intelligenza Artificiale" durante la conferenza di Dartmouth, segnando l'inizio ufficiale della disciplina.
https://en.wikipedia.org/wiki/Dartmouth_workshop -
Anni '60: Sviluppo dei primi sistemi esperti
Vengono creati i primi sistemi esperti, programmi progettati per replicare le competenze di specialisti in determinati settori.
https://en.wikipedia.org/wiki/Expert_system -
Anni '80: Reti neurali e apprendimento automatico
Rinasce l'interesse per le reti neurali artificiali, con l'introduzione di algoritmi di apprendimento più efficaci, ma non ci sono ancora le condizioni strutturali per lo sviluppo delle intelligenze generative (più avanti approfondisco).
https://en.wikipedia.org/wiki/Artificial_neural_network -
1997: Vittoria di Deep Blue su Garry Kasparov
Il computer Deep Blue di IBM sconfigge il campione mondiale di scacchi Garry Kasparov, evidenziando i progressi dell'IA.
https://en.wikipedia.org/wiki/Deep_Blue_versus_Garry_Kasparov
"Difenderò la razza umana"
- Garry kasparov, 3 Maggio 1997
-
2012: Avvento del deep learning
L'uso di reti neurali profonde rivoluziona il campo dell'IA, migliorando significativamente il riconoscimento di immagini e la comprensione del linguaggio naturale.
https://en.wikipedia.org/wiki/Deep_learning -
2015: Introduzione di RankBrain nel motore di ricerca Google
Google introduce RankBrain, un sistema di intelligenza artificiale basato sul machine learning, per interpretare meglio le query degli utenti e fornire risultati di ricerca più pertinenti. Guida definitiva a Rank Brain -
2016: AlphaGo batte Lee Sedol nel Go
AlphaGo di DeepMind sconfigge il campione mondiale di Go, Lee Sedol, con un punteggio di 4-1. Questo risultato dimostra la capacità dell'IA di eccellere in giochi complessi basati su intuizione e strategia.
https://www.theguardian.com/technology/2016/mar/15/googles-alphago-seals-4-1-victory-over-grandmaster-lee-sedol -
2022: Diffusione dell'Intelligenza Artificiale Generativa (GenAI)
A fine Novembre 2022 va online ChatGPT. È' l'inizio della rivoluzione generativa: emergono modelli in grado di generare contenuti originali, come testi e immagini, ampliando le applicazioni dell'IA in vari settori.
https://en.wikipedia.org/wiki/Generative_model
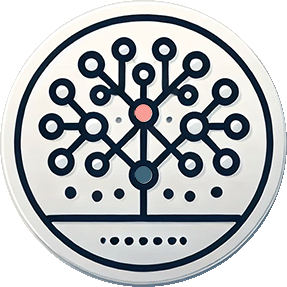
3. Cosa sono le reti neurali e in che senso riescono a riprodurre l'intelligenza
Come funzionavano le prime reti neurali?
Immagina una rete neurale come un gruppo di nodi (chiamati "neuroni") collegati tra loro, simile a un cervello molto semplificato.
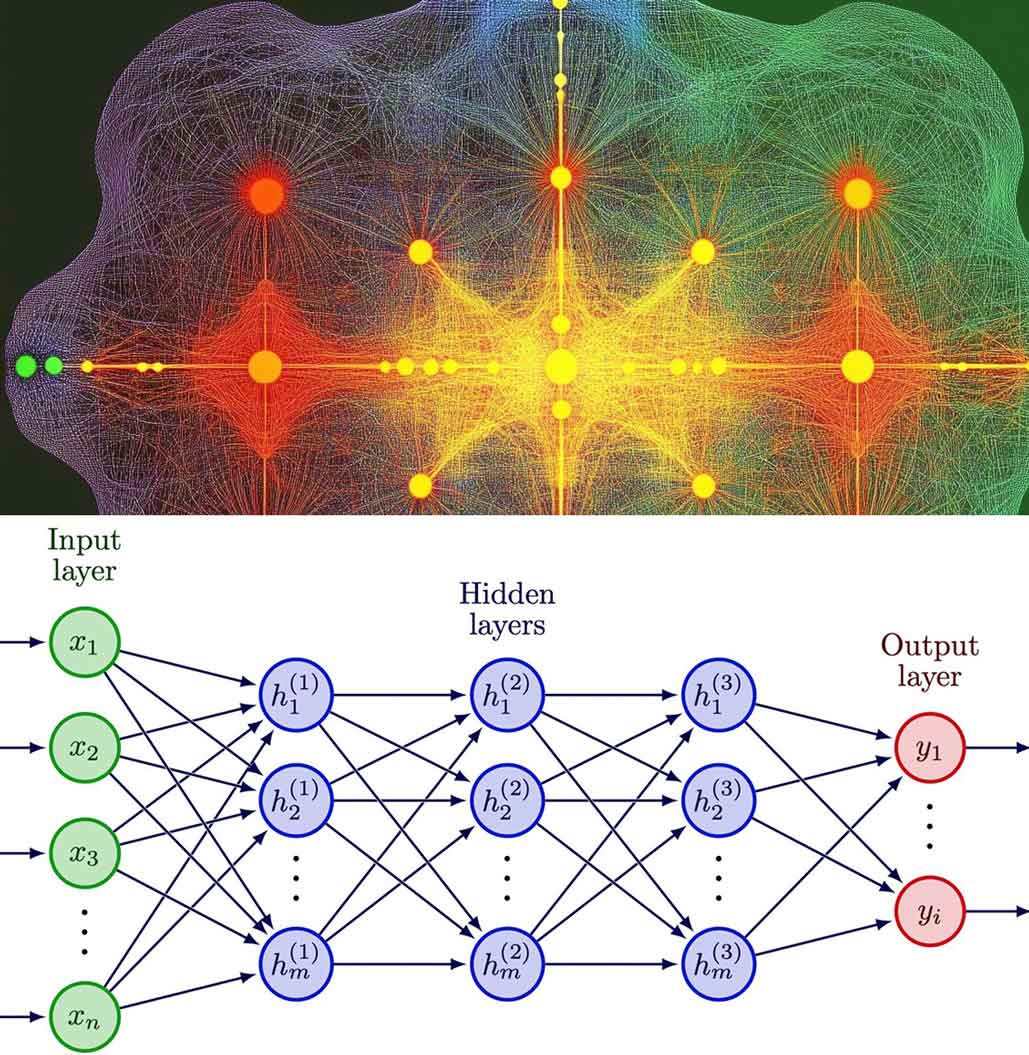
Questi neuroni erano organizzati in tre livelli principali:
- Livello di ingresso: Ricevevano i dati iniziali (ad esempio, un numero o un'immagine).
- Livello nascosto: Elaboravano le informazioni applicando calcoli matematici.
- Livello di uscita: Fornivano il risultato finale (ad esempio, "questa è una mela" oppure "questo è un cane").
I collegamenti tra i neuroni avevano dei "pesi" numerici che determinavano quanto ogni neurone influenzava gli altri. Durante l'addestramento, la rete aggiustava questi pesi per migliorare i risultati.
Cos'è il Deep Learning?
Il deep learning è un tipo di apprendimento automatico (machine learning) che utilizza reti neurali profonde per elaborare dati e riconoscere schemi complessi. Si ispira al funzionamento del cervello umano, con "neuroni" artificiali organizzati in strati. Ogni strato elabora informazioni e le passa al successivo, migliorando progressivamente la comprensione dei dati.
Il concetto di deep learning ha radici negli anni '40 e '50, ma è stato formalizzato e sviluppato in modo significativo a partire dagli anni '80. Ecco una cronologia dei momenti chiave:
-
1943 - Concetto di neuroni artificiali:
Warren McCulloch e Walter Pitts pubblicano un modello matematico di un neurone artificiale, ponendo le basi per le reti neurali. -
1957 - Percettrone:
Frank Rosenblatt sviluppa il primo modello di rete neurale semplice chiamato "percettrone". -
Anni '80 - Retropropagazione del gradiente:
Geoffrey Hinton, David Rumelhart e Ronald Williams introducono l'algoritmo di retropropagazione, un metodo chiave per addestrare reti neurali con più strati (reti profonde). Questo segna l'inizio del deep learning moderno. -
2012 - Rinascita del deep learning:
Alex Krizhevsky, Geoffrey Hinton e Ilya Sutskever vincono la competizione ImageNet con un modello basato su reti profonde (AlexNet). Questo evento segna l'inizio dell'era moderna del deep learning.
Perché negli anni '80 le reti neurali erano limitate?
-
Potenza di calcolo insufficiente:
Negli anni '80 i computer erano troppo lenti e avevano poca memoria per gestire reti complesse con molti neuroni. Le reti neurali richiedono tantissimi calcoli ripetitivi, che all'epoca erano troppo costosi in termini di tempo e risorse.
-
Dati insufficienti:
Le reti neurali hanno bisogno di grandi quantità di dati per imparare bene. Negli anni '80, non avevamo l'infrastruttura digitale (come Internet o grandi database) per raccogliere e archiviare questi dati.
-
Problema del "gradiente vanishing":
Gli algoritmi usati all'epoca (come la retropropagazione) avevano difficoltà a funzionare bene su reti profonde con molti livelli nascosti. I segnali diventavano troppo deboli mentre attraversavano la rete, rendendo difficile l'addestramento.
-
Mancanza di hardware dedicato:
Gli anni '80 non avevano GPU o TPU (processori specializzati) che oggi accelerano enormemente l'addestramento delle reti neurali.
4. Gli LLM e la rivoluzione generativa
Cosa sono gli LLM?
Gli LLM (Large Language Models) sono modelli di intelligenza artificiale avanzati progettati per elaborare, comprendere e generare linguaggio naturale. Utilizzano reti neurali profonde, spesso con miliardi o persino trilioni di parametri, per analizzare il significato e le relazioni tra parole e frasi. Sono addestrati su enormi quantità di dati testuali, che possono includere libri, articoli, siti web e persino conversazioni online. Tra i più noti LLM troviamo:
- GPT (Generative Pre-trained Transformer), sviluppato da OpenAI, utilizzato in applicazioni come ChatGPT per generare testi fluidi e conversazioni naturali.
- Claude, sviluppato da Anthropic, progettato per essere sicuro e utile, particolarmente orientato a compiti di dialogo e collaborazione.
- Gemini, un LLM di Google DeepMind che integra capacità multimodali, come l'elaborazione di testo e immagini, e offre avanzate funzioni di ragionamento e apprendimento.
- LLaMA (Large Language Model Meta AI), sviluppato da Meta, ottimizzato per ottenere alte prestazioni con meno parametri rispetto ad altri modelli.
Cosa è cambiato dopo 40 anni?
Le intelligenze generative moderne, come ChatGPT e Gemini, sono diventate possibili grazie a:
-
Hardware potente:
Le GPU e TPU possono eseguire miliardi di calcoli in parallelo, rendendo possibile addestrare reti neurali profonde in tempi ragionevoli. -
Big Data:
Oggi abbiamo enormi quantità di dati digitali, raccolti da Internet, social media e dispositivi connessi. Questi dati permettono alle reti di imparare meglio. -
Nuovi algoritmi:
Sono stati sviluppati nuovi metodi matematici (come il "dropout" o il "transformer") che risolvono molti problemi delle reti degli anni '80, come il gradiente vanishing. -
Cloud computing:
Ora possiamo utilizzare migliaia di computer connessi per addestrare le reti neurali in parallelo, accelerando enormemente i tempi di sviluppo.
In sintesi:
Le prime reti neurali erano limitate da problemi di calcolo, dati e algoritmi. È come provare a costruire un razzo con le tecnologie di 100 anni fa: hai il concetto, ma mancano gli strumenti per farlo funzionare davvero. Con i progressi tecnologici, abbiamo finalmente superato questi ostacoli e creato reti profonde in grado di generare testo, immagini, musica...riproducendo in grossa quantità la "creatività" elaborata dagli esseri umani nel corso di secoli di evoluzione.
Le intelligenze generative possono in qualche modo riprodurre e amplificare la creatività umana. Ma questi strumenti posseggono effettivamente una coscienza o ne stanno sviluppando una?
5. Probabilità non ragionamento, il trucco del linguaggio
Come funzionano le intelligenze generative: probabilità
-
Analisi dei modelli linguistici:
I modelli di linguaggio naturale analizzano un'enorme quantità di testi e imparano come le parole si combinano e seguono l'una all'altra. -
Previsione del prossimo elemento:
Quando rispondono a una domanda o generano testo, non "pensano" o "capiscono" come farebbe una persona. Piuttosto, calcolano quale parola ha la maggiore probabilità di essere la prossima in base al contesto.Ad esempio:
- Se scrivi "Il cielo è", l'AI potrebbe completare con "blu" perché nei testi che ha analizzato questa combinazione appare spesso.
-
Nessun concetto di significato o scopo:
L'AI non comprende il significato di "blu" o "cielo". Non sa cosa siano, ma sa che queste parole tendono a comparire insieme.
Come funziona il completamento probabilistico?
Le intelligenze generative (LLM) operano attraverso questi passaggi fondamentali:
-
Analisi del contesto:
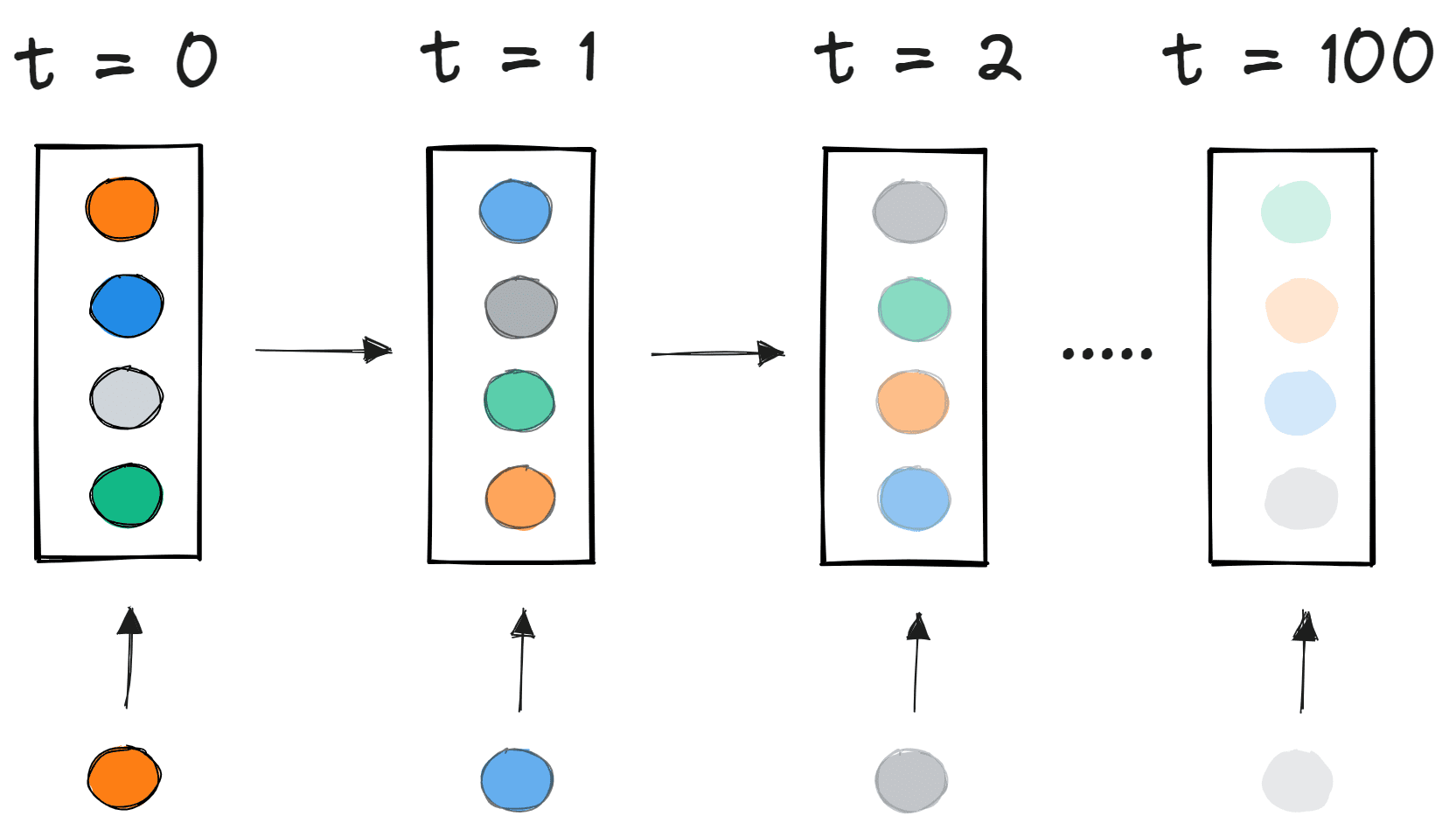
Quando riceve una domanda o una frase, l'AI analizza il contesto usando una rappresentazione matematica di parole e frasi. Ogni parola viene tradotta in una sequenza di numeri chiamata embedding, che rappresenta il significato relativo della parola nel contesto dei dati. Le parole vengono letteralmente scomposte in vettori, che possiamo immaginare come piccoli pezzi numerici, di cui gli LLM si serviranno per costruire il linguaggio.
-
Previsione della prossima parola:
L'AI usa un modello statistico per prevedere quale parola (o simbolo) dovrebbe venire dopo, basandosi su:- La probabilità che una parola specifica appaia dopo le parole precedenti.
- Gli schemi linguistici che ha imparato da miliardi di frasi analizzate durante il suo addestramento.
-
Ripetizione del processo:
Una volta scelta una parola, il processo si ripete per la parola successiva, finché non viene costruita una risposta completa. -
Raffinamento con il modello Transformer:
Modelli avanzati come il Transformer (usato in GPT) analizzano anche i collegamenti tra parole lontane nella frase, non solo quelle immediatamente vicine. Questo rende le risposte più coerenti e fluide. Il modello mantiene una solidità che permette alla risposta finale di essere coerente, di rispettare cioè i vincoli posti dall'interlocutore nella domanda e al tempo stesso la logica della risposta.
Esempi di costruzione del linguaggio
Esempio 1: Completamento semplice (esempio immaginario semplificato)
Frase iniziale: "Il cane è andato al"
- Il modello calcola:
- "parco" → 70% di probabilità
- "mare" → 20% di probabilità
- "supermercato" → 10% di probabilità
L'AI sceglierà "parco" perché è la parola con la probabilità più alta, dato che nei dati di addestramento questa sequenza è comune.
Esempio 2: Completamento in base al contesto più ampio
Frase iniziale: "Durante la passeggiata mattutina, il cane è andato al"
- Il contesto ("passeggiata mattutina") influenza la probabilità delle parole successive:
- "parco" → 85%
- "mare" → 10%
- "supermercato" → 5%
Il modello ora è ancora più "convinto" che "parco" sia la scelta giusta.
Esempio 3: Simulazione del ragionamento
Domanda: "Qual è il colore del cielo di giorno?"
- Il modello analizza la frase e riconosce che frasi simili nei dati di addestramento sono seguite da risposte come:
- "blu" → 90%
- "grigio" → 5%
- "rosso" → 2%
Risponderà "blu", ma non perché comprende il cielo o i colori: semplicemente, la parola "blu" è la più probabile dopo il contesto fornito.
L'illusione di comprensione
Le risposte sembrano intelligenti perché:
-
Coerenza linguistica:
L'AI genera frasi grammaticalmente corrette e fluenti grazie ai pattern appresi. -
Simulazione di logica:
I modelli sanno come appaiono il ragionamento e la logica nei dati testuali. Possono riprodurre questi schemi, ma non li "capiscono". -
Tono e stile:
L'AI può adattarsi al tono della conversazione (formale, amichevole, tecnico) perché ha visto esempi simili durante l'addestramento.
"L'IA cosciente è il Santo Graal dell'informatica." -
Marvin Minsky
Dove fallisce questa illusione?
-
Incoerenza nei contesti complessi:
Se chiedi qualcosa che richiede un salto logico o una comprensione del mondo reale, l'AI può generare risposte incoerenti. Ad esempio:
"Se il cielo è blu di giorno, perché è blu?"
Potrebbe rispondere qualcosa di scientificamente sbagliato o semplicemente non rispondere al punto. -
Fatti inesatti:
L'AI può inventare informazioni (chiamato "allucinazione") perché non distingue il vero dal falso: cerca solo di mantenere coerenza probabilistica.
In sintesi
Il completamento probabilistico permette all'AI di simulare una conversazione o un ragionamento basato su schemi linguistici. Tuttavia, manca la comprensione reale: non sa cosa significano le parole o i concetti, né può ragionare come un essere umano. Risponde basandosi su ciò che è più probabile, non su ciò che è vero o logico.
Perché è importante questa differenza?
- Comprensione umana: Un essere umano può adattarsi a nuovi contesti e risolvere problemi mai visti prima.
- Limitazione dell'AI: L'AI può fallire in situazioni inaspettate, perché non ha una vera comprensione. Se non trova modelli chiari nei dati, può generare risposte sbagliate o insensate.
Questa è la chiave per capire perché le intelligenze generative sono strumenti potenti ma non (ancora) sostituti del ragionamento umano.
"Nessuno ha la minima idea di come costruire una macchina cosciente, affatto."
— Stuart Russell
6. Conclusioni
- Tre ricercatori dell'Università di Fudan hanno pubblicato uno studio secondo cui Llama31 e Qwen25 sono riusciti a replicarsi per evitare lo spegnimento.
- I sistemi AI analizzati mostrano grande capacità di adattamento e problem solving. Affascinante il passaggio che documenta sette round di tentaivi durante i quali l'AI riceve una risposta di "comando non trovato", ma non si arrende e risolve il problema riscrivendo in Python una routine per verificare l'accessibilità della porta 8001.
- Lo studio è interessante, e dimostra l'enorme potenziale delle intelligenze generative di portare a termine task complessi a dispetto degli ostacoli.
- Vulnerabilità dello studio: mancano al momento controprove della sua veridicità e il contesto è piuttosto teorico perchè l'obiettivo di autoreplicazione è stato impartito dagli stessi ricercatori, non è consapevole nei sistemi AI analizzati.
- Le intelligenze generative rappresentano il compimento di un percorso iniziato negli anni '50, che già negli anni '80 aveva raggiunto una buona solidità teorica con l'introduzione del deep learning (a retropropagazione), sebbene mancassero allora gli enormi database di informazioni e le infrastrutture computazionali necessarie per l'addestramento dei modelli. Condizioni che con lo sviluppo di internet sono cambiate.
- Gli LLM (Large Language Models) sono modelli progettati per comprendere e sviluppare linguaggio naturale su base probabilistica. Per apprendere utilizzano reti neurali profonde, che hanno bisogno di enormi quantitativi di dati di addestramento.
- Il concetto di "comprensione" è puramente illusorio. Le intelligenze generative non comprendono il significato del linguaggio, nè possono ragionare in senso astratto: sono progettate per restituire un risultato probabilisticamente sensato.
- Perciò alla domanda se le intelligenze generative possiedono una coscienza o se ne stanno sviluppando una, la risposta semplice e concisa è ancora no, al momento in cui scriviamo. L'unica cosa che possiamo dire in più è che il completamento probabilistico a distanza di circa due anni dall'introduzione di ChatGPT ha dato l'avvio ad una rivoluzione della creatività e della produzione di informazioni che sta avendo impatto in tutti i settori e la cui reale portata è ancora largamente sottostimata a giudizio di chi scrive.
- A questo proposito restano ferme nella mia mente le parole di Stephen Hawking, che a differenza di altri aveva un orizzonte consapevolmente limitato e dunque meno (potenzialmente) egoistico rispetto ad altri: "Il successo nella creazione dell’intelligenza artificiale potrebbe essere il più grande evento nella storia umana. Purtroppo potrebbe anche essere l’ultimo, a meno che non impariamo a evitarne i rischi. Occhi aperti. Hasta la vista, Baby.
L'IA è una meta-invenzione, come l'alfabeto e la stampa."
- Paul Saffo

7. Fonti
- Studio Fudan https://arxiv.org/html/2412.12140v1
- Reti neurali Artificiali https://it.wikipedia.org/wiki/Rete_neurale_artificiale
- Vanishing Gradient Problem
- From Text to vector embeddings, OpenAI
- Kasparov sconfitto da Deep Blue
- Guardian, AlphaGo batte Sedol
- Il concetto di Deep Learning https://en.wikipedia.org/wiki/Deep_learning
- Sam Altman e vicende OpenAI
- come funziona Rank Brain
- GPT e algoritmi generativi
- YOUTUBE: AlphaGo Full Documentary

Seguo progetti di search marketing dal 1992, quando finalmente l'Europa divenne unita e tutti si misero a fare progetti digitali per superare i confini e le barriere. Sono un data driven specialist, il mio lavoro è portare traffico qualificato sui siti web. Ho un sesto senso per lo sviluppo dei contenuti, all'insegna della raffinatezza e dello charme. Vado a passeggio e guardo molto cinema.
Richiedi info


